
.png)
Hybrid Search & Agentic RAG for Enhanced Data Retrieval
- Javith Abbas
- Feb 21
- 3 min read

Updated: Mar 4
Retrieval-Augmented Generation (RAG) frameworks have emerged as a powerful solution, allowing language models to generate responses grounded in real-world data.
However, traditional retrieval methods often struggle with messy, mixed-type data or exact keyword queries. This is where Hybrid Search and Agentic RAG come into play, transforming our approach to data retrieval. In this blog, I’ll share insights from my experience working with these systems, a blend of technical exploration and practical implementation. Whether you’re preparing for an interview or evaluating advanced retrieval strategies for an enterprise project, I hope this serves as a valuable resource.
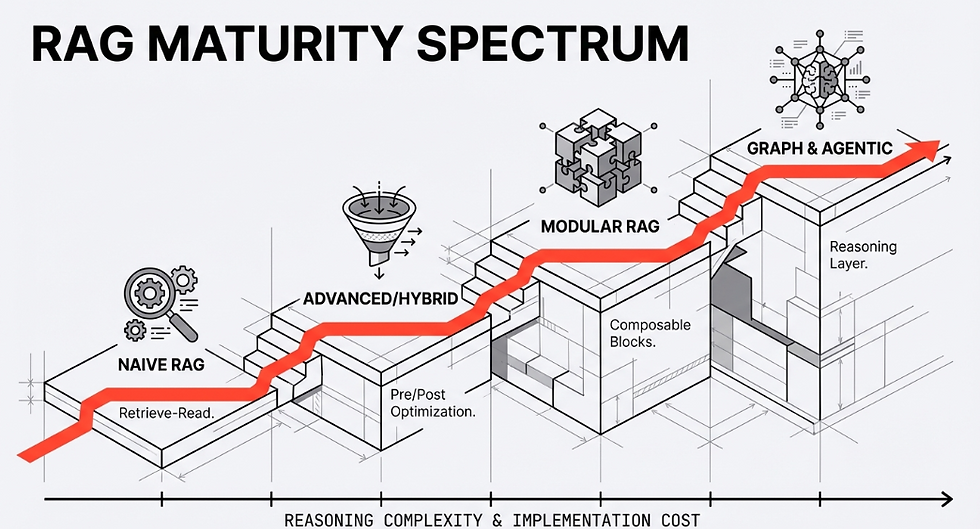
Why Hybrid Search Matters
Hybrid Search in RAG combines two fundamentally different retrieval mechanisms:
1. Semantic Vector Search: This method uses dense embeddings to understand the meaning and context behind a query. For example, if someone asks, "Explain our customer churn modeling approach," semantic search excels at capturing intent, even if the phrasing differs from the stored content.
2. Lexical Search: Traditional keyword-based methods like BM25 or TF-IDF focus on exact term matches. This approach is crucial for retrieving specific identifiers, such as contract numbers ("Show me SLA terms in contract 2022-AC-455"). While semantic search is adept at understanding general intent, it often struggles with exact keyword compliance. I faced this limitation firsthand when a vector-only RAG system I implemented failed to retrieve specific policy numbers buried within structured documents. Hybrid search bridges this gap by combining the strengths of both methods, ensuring we capture both deep semantic meaning and precise terminology.
How Hybrid Search Works
The hybrid search process can be broken down into three main steps:
Parallel Retrieval
When a user submits a query, the system simultaneously performs:
- Dense Retrieval: Using semantic embeddings to find contextually similar documents.
- Sparse Retrieval: Using keyword-based approaches to locate exact matches.
Merging and Reranking
After retrieving results from both methods, the next challenge is combining them into a unified ranking. Algorithms like Reciprocal Rank Fusion (RRF) help with this. RRF rescales and merges the scores from both retrieval methods, ensuring documents consistently identified as relevant by both approaches are ranked higher.
Generation
Once the results are merged and ranked, the system passes the enriched list of highly relevant chunks to the language model (LLM). The LLM then generates a grounded response based on the retrieved data.
Enhancing Recall with Agentic RAG and Multi-Query Techniques
Even with hybrid search, recall can suffer due to ambiguous user prompts. This is where Agentic RAG and multi-query techniques come into play, expanding the query space and maximizing retrieval coverage.
How Multi-Query Techniques Work
The core idea is straightforward: instead of relying on a single query, the agent generates multiple paraphrased variations of the user’s original question. This ensures we capture different angles, synonyms, and domain-specific phrasing that the user might not have included.
Steps
Query Generation (Paraphrasing): Using an LLM, generate 3–5 variations of the original query.
Parallel Retrieval: Each variation is independently searched across the vector database or multiple data sources.
Aggregation and Reranking: The retrieved results are aggregated using Reciprocal Rank Fusion to create a unified list.
Why This Works
Multi-query techniques enhance recall by capturing diverse query phrasing, ensuring no relevant document is overlooked due to vocabulary mismatches. This approach has been a game-changer for me when working with large enterprise datasets, where user queries often fail to align with the terminology stored in the knowledge base.
Enterprise Benefits
Implementing hybrid search and multi-query techniques has significantly improved the precision, recall, and robustness of the systems I’ve worked on. Here are some key benefits:
Higher Precision and Recall
By leveraging the complementary strengths of semantic and lexical search, hybrid retrieval consistently outperforms single-method approaches. In my experience, precision improved by 10–15%, while recall increased by 10–20%.
Reduced Errors
Hybrid search minimizes false negatives by capturing exact terms and reduces false positives by filtering out semantically drifted results. This balance is critical for enterprise systems dealing with sensitive data.
Production Readiness
Hybrid search is particularly suited for messy, mixed-type data found in regulatory environments and enterprise platforms. Its reliability and flexibility make it the default standard for production systems.
Final Takeaways
Hybrid Search and Agentic RAG represent a paradigm shift in how we approach information retrieval in AI systems. This is the de facto standard of all RAG as a service solutions like Azure AI Search, LlamaCloud etc. If you are just starting with RAG then you need to be aware of these.


Comments